
Figure: Generated from our Art VM Image using Invoke AI
Previously we performed some benchmarks on Llama 3 across various GPU types. We are returning again to perform the same tests on the new Llama 3.1 LLM. On July 23, 2024, the AI community welcomed the release of Llama 3.1 405B, 70B and 8B models. These models are the next version in the Llama 3 family. Below is a video of Mark Zuckerberg discussing the release of Llama 3.1 and other AI topics.
Just a note before going further. The structure of this post is very similar to the benchmark of Llama 3 70B. Note that all the data provided below is in fact for Llama 3.1 70B.
The GPUs Tested
Before diving into the results, let’s briefly overview the GPUs we tested:
- NVIDIA A30: Professional-grade graphics card designed for data centers and AI applications, offering high-performance computing, advanced memory, and energy efficiency.
- NVIDIA A6000: Known for its high memory bandwidth and compute capabilities, widely used in professional graphics and AI workloads.
- NVIDIA L40: Designed for enterprise AI and data analytics, offering balanced performance.
- NVIDIA A100 SXM4: Another variant of the A100, optimized for maximum performance with the SXM4 form factor.
- NVIDIA H100 PCIe: The latest in the series, boasting improved performance and efficiency, tailored for AI applications.
Benchmarking Methodology
There are many different engines and techniques we could have used to judge performance across the various GPUs. We decided to leverage the Hugging Face Text Generation Inference (TGI) engine as the primary way to serve Llama 3.1 70B. This was done for one primary reason. The benchmarking functionality with Hugging Face TGI is incredibly easy to use.
The benchmark tools provided with TGI allows us to look across batch sizes, prefill, and decode steps. It is a fantastic way to view Average, Min, and Max token per second as well as p50, p90, and p99 results. If you want to learn more about how to conduct benchmarks via TGI, reach out we would be happy to help.
Results
A30
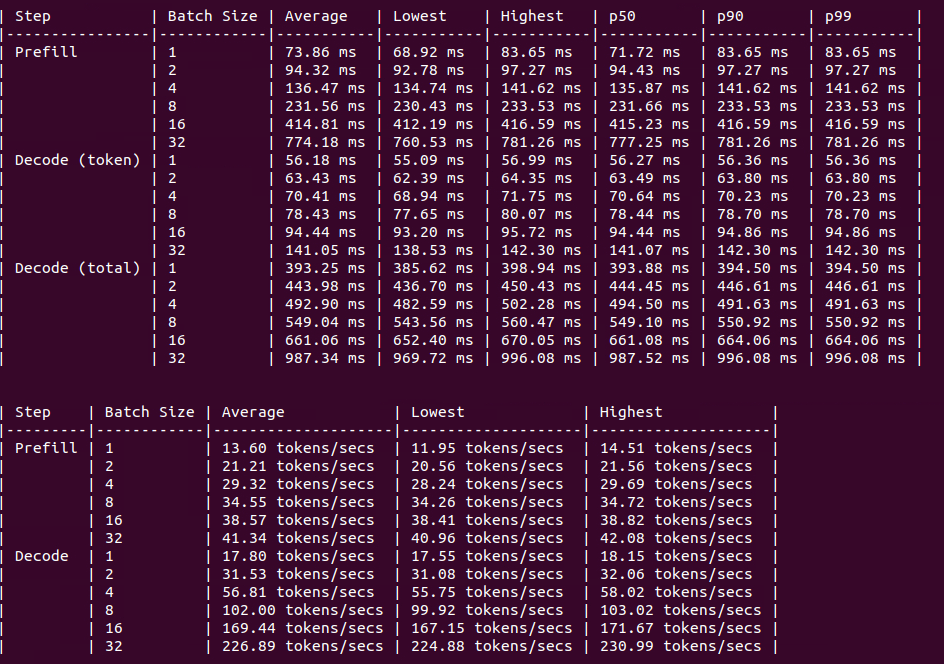
Figure: Benchmark on 8xA30
RTX A6000
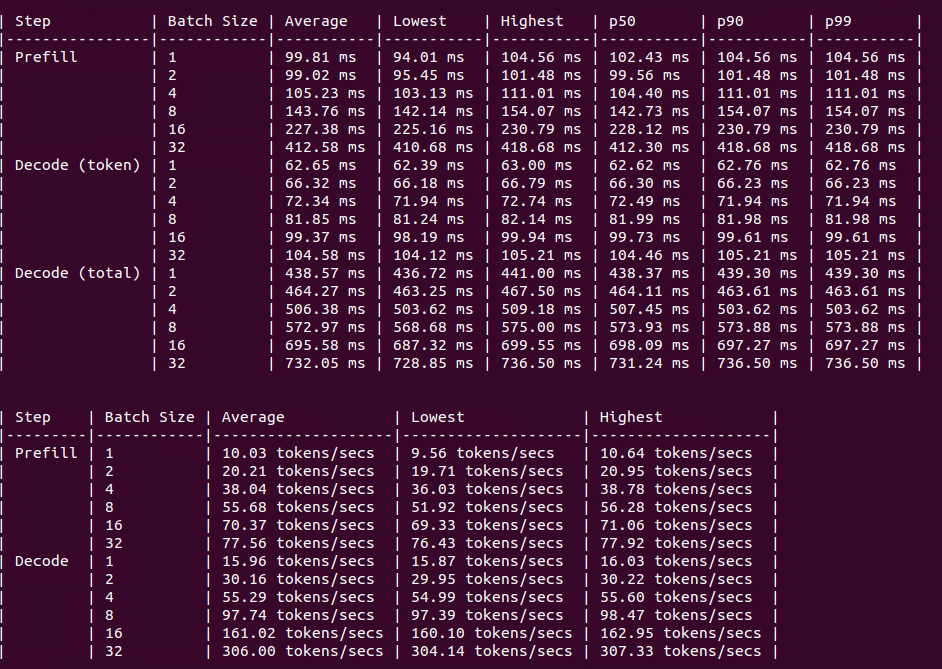
Figure: Benchmark on 4xA6000
L40
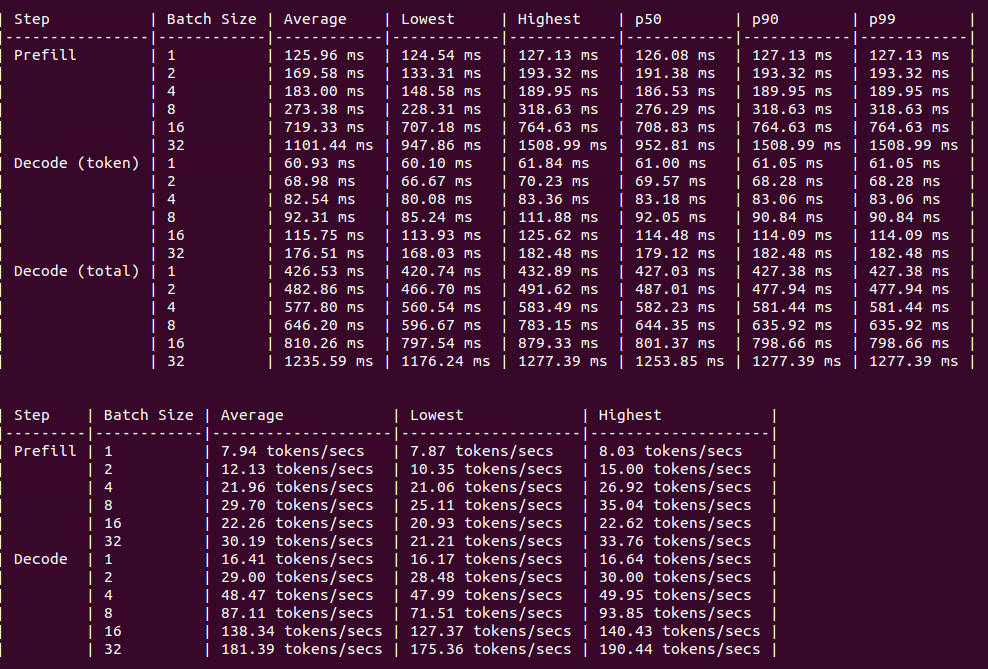
Figure: Benchmark on 4xL40
A100 SXM4
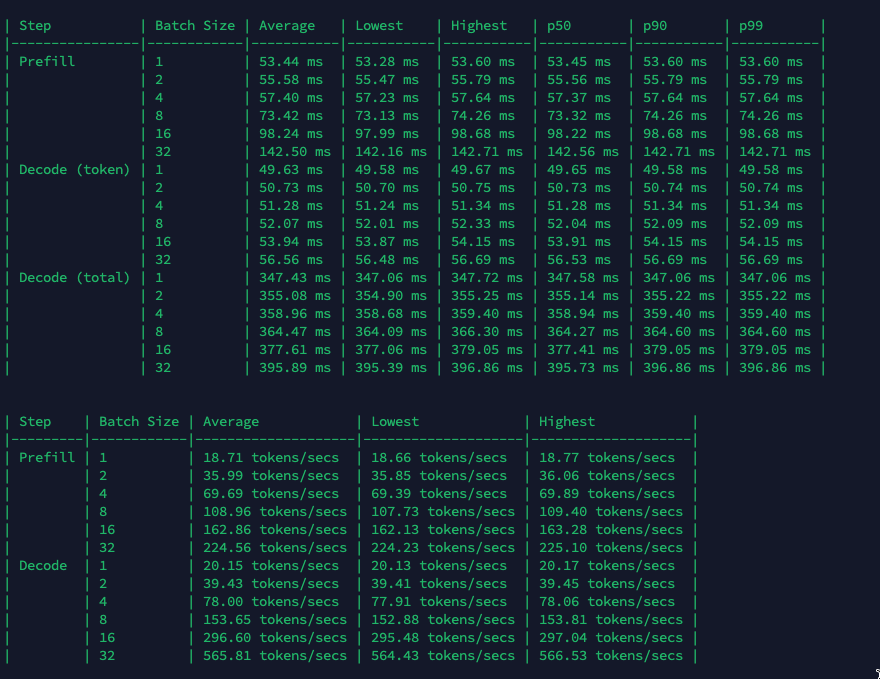
Figure: Benchmark on 2xA100
H100 PCIe
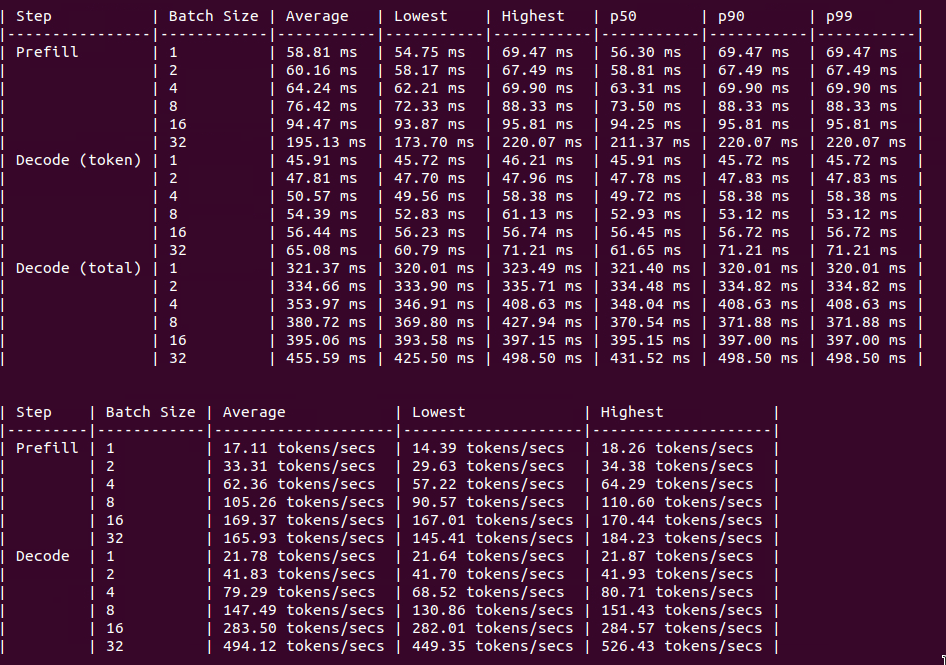
Figure: Benchmark on 2xH100
Conclusion
Hugging Face TGI provides a consistent mechanism to benchmark across multiple GPU types. Based on the performance of theses results we could also calculate the most cost effective GPU to run an inference endpoint for Llama 3.1. Understanding these nuances can help in making informed decisions when deploying Llama 3.1 70B, ensuring you get the best performance and value for your investment.
If you want to try and replicate these results check out our marketplace to rent a GPU Virtual Machine. Sign Up and within a few minutes you can have a working VM to test these results.