
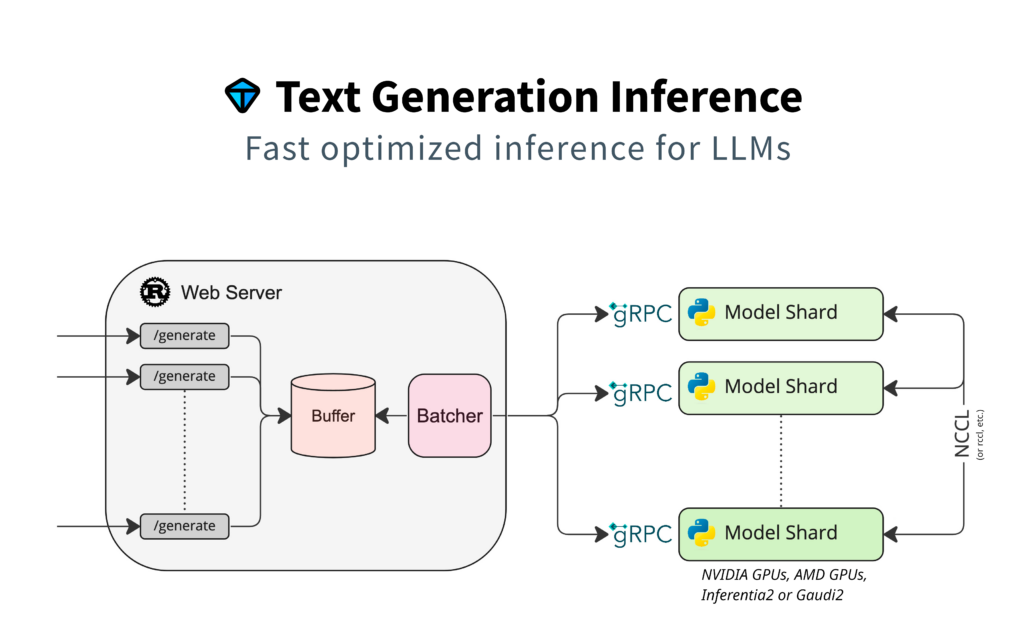
Introduction – Multiple LLM APIs
If you haven’t already, go back and read Part 1 of this series. In this guide we take a look at how you can serve multiple models in the same VM.
As you start to decide how you want to serve models as an inference endpoint you have a few options available to manage the resources needed to serve those models. You could deploy an instance per modal OR you could deploy a single instance that serves multiple models. The single instance would likely have multiple GPUs that allows you to pick which GPU each model is served on.
In this part of the series we look at how you can leverage larger VM instances and pick and choose what GPUs each model is using.
Rent a VM Today!Tools needed
- A Massed Compute Virtual Machine
- Category: Bootstrap
- Image: LLM API
- Docker
Preparation
Managing multiple models can be confusing. There are more pieces of the puzzle to track and keep straight. A little preparation work can help make the setup steps run smoothly. Here is what you will need to do:
- Find your models of interest. In this example we will use the following
- Determine how many GPUs you need to serve the various models. Typically the following is true but you may have to experiment per model. In our case we are using a 2xA6000 VM because we have two 7b models we want to serve and each requires a single A6000.
- 7b models – 1 A6000
- 13b models – 1 or 2 A6000
- 34b models – 2 A6000
- 70b models – 4 A6000
- Mixture of Experts (MoE) models – 4 A6000
- Each model you want to serve as an endpoint will need a unique port. In this case we will assign the following ports
-
8080– Zephyr 7b8081– OpenHermes 7b
-
Steps to get Setup
- Our Virtual Machine’s come pre-installed with Docker and have a Welcome doc. These steps will be slightly different than what is in that welcome doc. Start by navigating to Hugging Face and find a model of interest. On the model page copy the model id which we will use later.
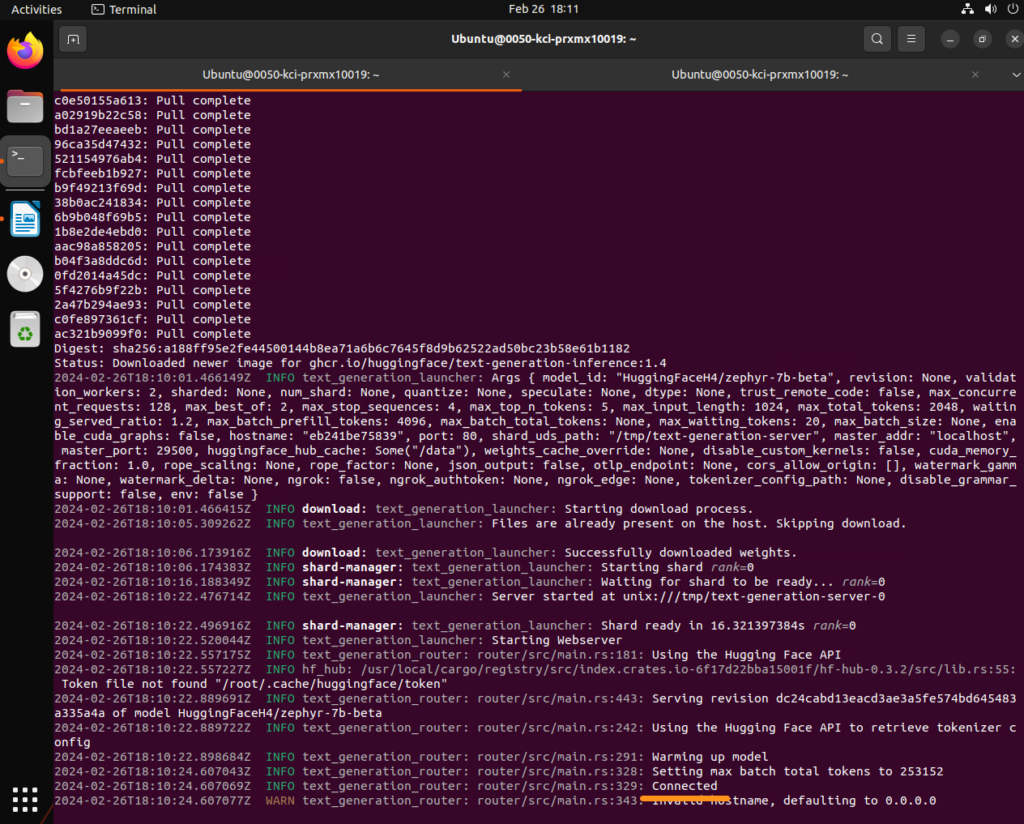
3. Now for some work in the terminal. Run these commands in order
mkdir datavolume=$PWD/datamodel=HuggingFaceH4/zephyr-7b-beta
4. Then run the following to spin up a docker container serving the Zephyr model.
docker run --gpus '"device=0"' --shm-size 1g -p 8080:80 -v $volume:/data ghcr.io/huggingface/text-generation-inference:1.4 --model-id $model- You may have to run `sudo` in front of the docker command
5. Next lets prepare and load the OpenHermes model. Open a new tab in the terminal and run the following in order
volume=$PWD/datamodel=teknium/OpenHermes-2.5-Mistral-7B
6. Then run the following to spin up a docker container serving the OpenHermes model.
docker run --gpus '"device=1"' --shm-size 1g -p 8081:80 -v $volume:/data ghcr.io/huggingface/text-generation-inference:1.4 --model-id $model- You may have to run `sudo` in front of the docker command
Some important pieces in this command
--gpus '"device=0"'This means the model will be leveraging the first available GPU within the VM. It will only load the model on the first GPU.--gpus '"device=1"'This means the model will be leveraging the second available GPU within the VM. It will only load the model on the second GPU.-pThis is the Port the API request can be made to to hit the model--model-idThis is what model the container will load. We already set the $model variable above in step three.
There are many more parameters that you can learn about on Hugging Face’s website for Text Generation Inference.
Once the model is fully downloaded and ready to use, you can then make API requests against this model.
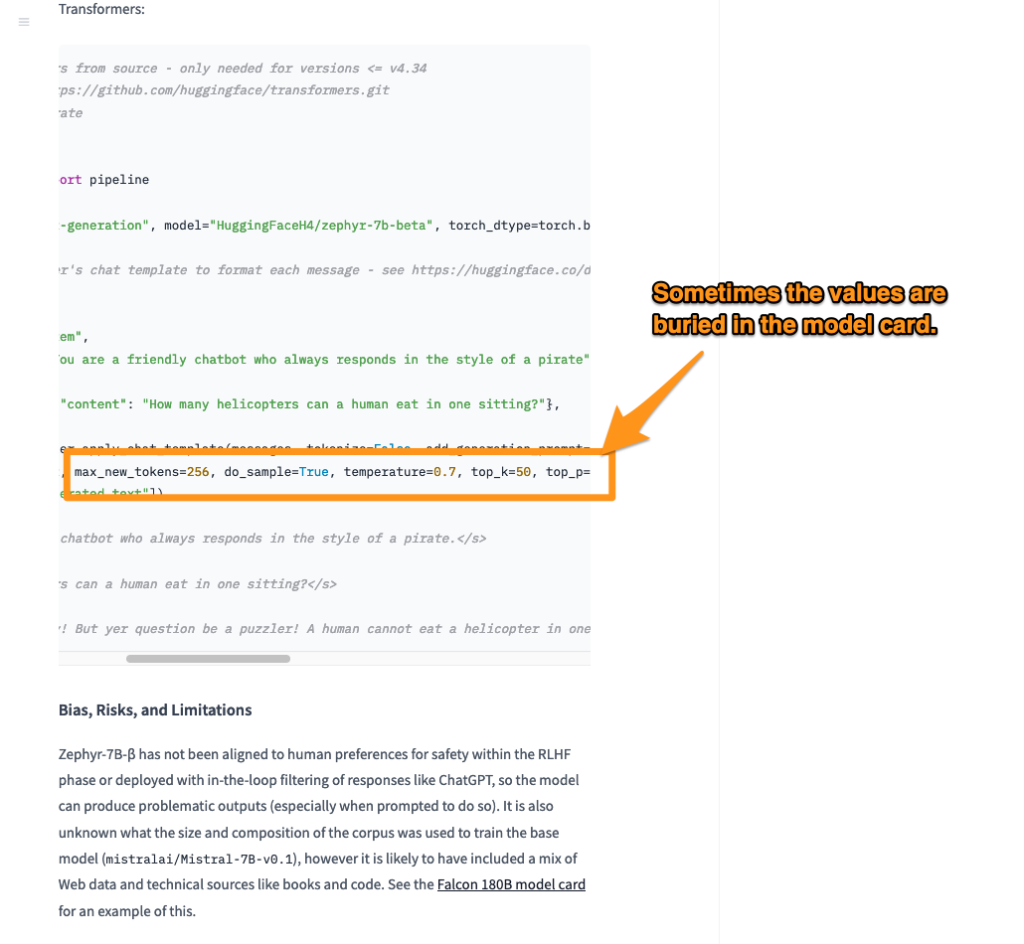
7. To make an API request against this model you will need a few variables.
From the Model Card on Hugging Face
- max_new_tokens
- temperature
- top_k
- top_p
Some times these can be hard to find, but most model cards have this information available.
Information from other sources
Massed Compute VM IP– When you provision a VM you will be provided an IP address
Pull it all together
Making request to Zephyr:
curl -X POST
MASSED_COMPUTE_VM_IP:8080/generate
-H 'Content-Type: application/json'
-d '{"inputs":"<|system|>You are a friendly chatbot.n<|user|>Why is the sky blue?n<|assistant|>","parameters":{"do_sample": true, "max_new_tokens": 256, "repetition_penalty": 1.15, "temperature": 0.7, "top_k": 50, "top_p": 0.95, "best_of": 1}}'
If you want to make stream api requests use the /generate_streamendpoint
curl -X POST
MASSED_COMPUTE_VM_IP:8080/generate_stream
-H 'Content-Type: application/json'
-d '{"inputs":"<|system|>You are a friendly chatbot.n<|user|>Why is the sky blue?n<|assistant|>","parameters":{"do_sample": true, "max_new_tokens": 256, "repetition_penalty": 1.15, "temperature": 0.7, "top_k": 50, "top_p": 0.95, "best_of": 1}}'
Making request to OpenHermes:
curl -X POST
MASSED_COMPUTE_VM_IP:8081/generate
-H 'Content-Type: application/json'
-d '{"inputs":"<|system|>You are a friendly chatbot.n<|user|>Why is the sky blue?n<|assistant|>","parameters":{"do_sample": true, "max_new_tokens": 256, "repetition_penalty": 1.15, "temperature": 0.7, "top_k": 50, "top_p": 0.95, "best_of": 1}}'
If you want to make stream api requests use the /generate_streamendpoint
curl -X POST
MASSED_COMPUTE_VM_IP:8081/generate_stream
-H 'Content-Type: application/json'
-d '{"inputs":"<|system|>You are a friendly chatbot.n<|user|>Why is the sky blue?n<|assistant|>","parameters":{"do_sample": true, "max_new_tokens": 256, "repetition_penalty": 1.15, "temperature": 0.7, "top_k": 50, "top_p": 0.95, "best_of": 1}}'
8. Integrate your project with this new inference endpoint.
How can I see that my model is loaded?
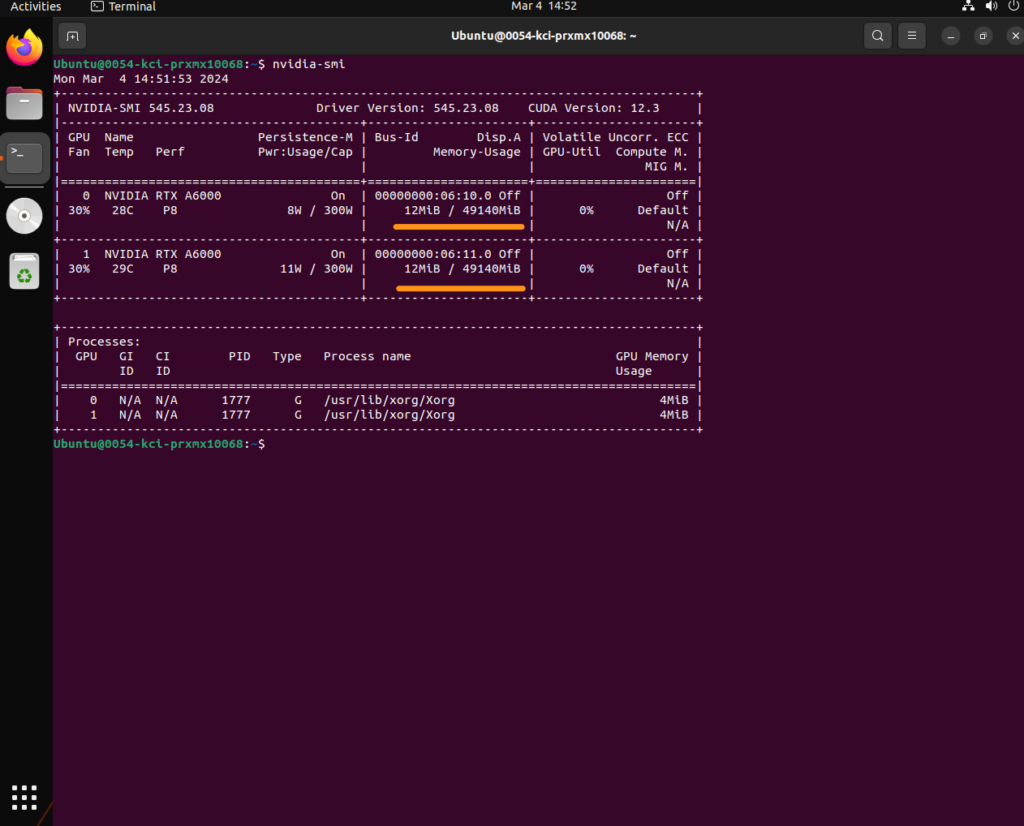
A great question. There are some commands that you can use to review the VM hardware to make sure your model is loaded. A slightly differnt command than from Part 1 but gives you the same information nvidia-smiThis command lets you review all the system resources
Before a model is loaded:
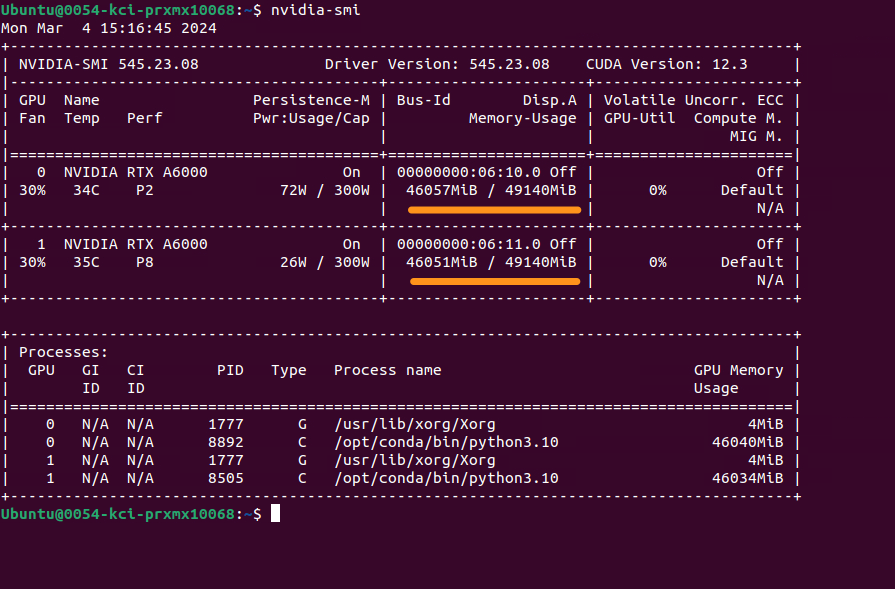
After a model is loaded. You can now see the GPU resources fully loaded the model.
Conclusion
Leveraging Hugging Face’s Text Generation Inference you can easily deploy full unquantized models in the matter of minutes. Depending on your preferred style to manage resources you may find yourself wanting to manage all your inference endpoints in a single resource. This guide should help show how leveraging TGI docker containers allows you to load multiple models across a larger VM.
Rent a VM Today!