
Category: How To
-

One-Click Easy Install of ComfyUI
DISCLAIMER: Some ComfyUI nodes have been found to contain malicious code. Article discussing the issue. While ComfyUI itself remains secure, a malicious custom node uploaded…
-

Best Llama 3 Inference Endpoint – Part 2
In Part 1, we looked at how tools like Ollama, LM Studio, and Text Generation WebUI perform as an inference endpoint for Llama 3 –…
-

Best Llama 3 Inference Endpoint – Part 1
With the exciting launch of Meta’s Llama 3 LLM, we were curious about which application would be the best to serve Llama 3 as an…
-

Leverage Hugging Face’s TGI to Create Large Language Models (LLMs) Inference APIs – Part 2
Introduction – Multiple LLM APIs If you haven’t already, go back and read Part 1 of this series. In this guide we take a look…
-

Leverage Hugging Face’s TGI to Create Large Language Models (LLMs) Inference APIs – Part 1
Introduction Are you interested in setting up an inference endpoint for one of your favorite models? Have you been wanting to leverage the full unquantized…
-
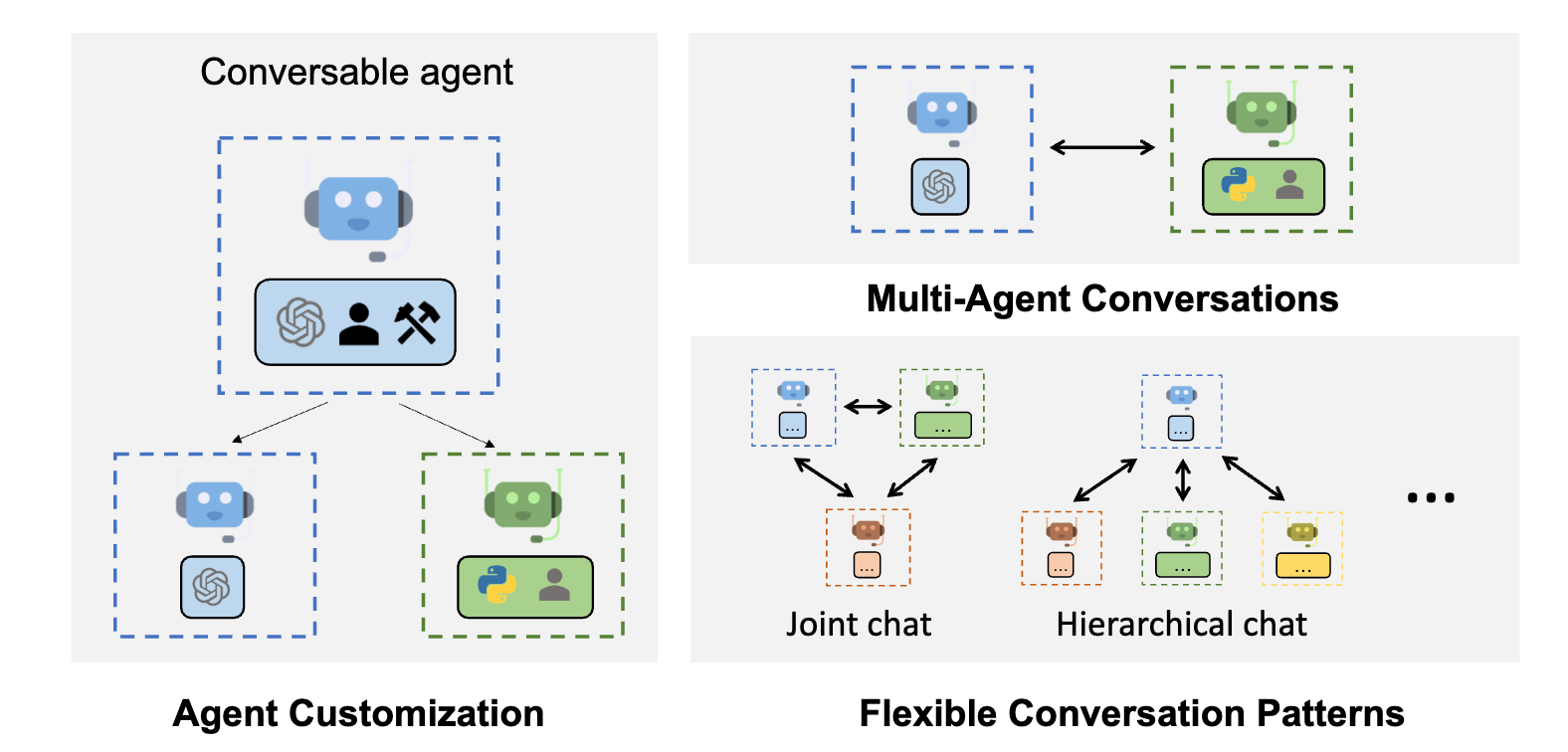
AutoGen with Ollama/LiteLLM – Setup on Linux VM
In the ever-evolving landscape of AI technology, Microsoft continues to push the boundaries with groundbreaking projects. Among these innovative endeavors is their AutoGen project. AutoGen…