
We’ve all experienced AI hallucinations—those moments when a chatbot or AI assistant confidently provides an answer that is completely wrong. AI models rely on pre-trained data and often lack access to real-time, company-specific information. When forced to answer, they may fabricate responses rather than admit gaps in their knowledge. RAG solves this problem by allowing […]
Category Archives: How To
How To, Hugging Face, LLM
Leverage Hugging Face’s TGI to Create Large Language Models (LLMs) Inference APIs – Part 2

04
Mar
Mar
Introduction – Multiple LLM APIs If you haven’t already, go back and read Part 1 of this series. In this guide we take a look at how you can serve multiple models in the same VM. As you start to decide how you want to serve models as an inference endpoint you have a few […]
How To, Hugging Face, LLM
Leverage Hugging Face’s TGI to Create Large Language Models (LLMs) Inference APIs – Part 1

26
Feb
Feb
Introduction Are you interested in setting up an inference endpoint for one of your favorite models? Have you been wanting to leverage the full unquantized version of models but found the process too complex or time-consuming? Do you wish there was a simple and efficient way to deploy full models for your own projects or […]
29
Nov
Nov
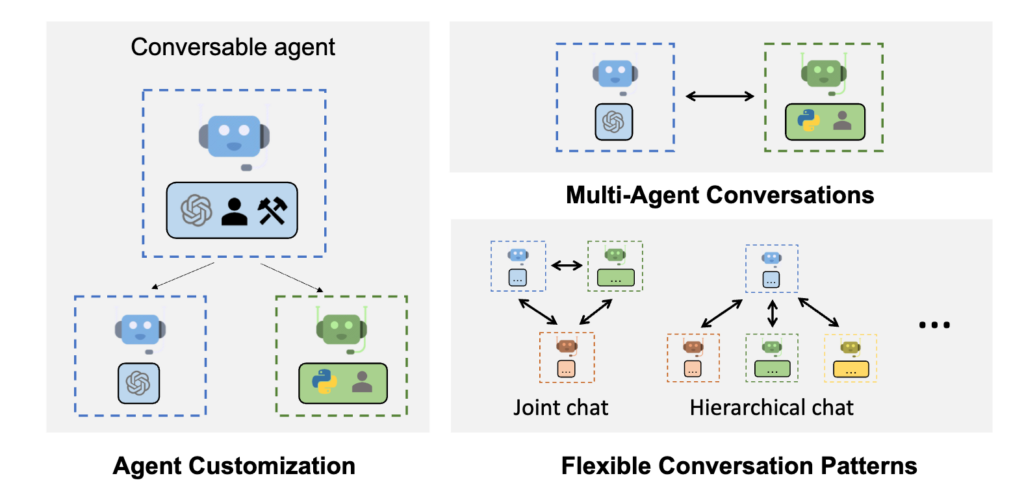
In the ever-evolving landscape of AI technology, Microsoft continues to push the boundaries with groundbreaking projects. Among these innovative endeavors is their AutoGen project. AutoGen provides multi-agent conversation framework as a high-level abstraction. With this framework, one can conveniently build LLM workflows. As developers grapple with the increasing complexity of modern software applications, AutoGen offers […]