Massed Compute Blog

How to Find the ROI Sweet Spot in AI Infrastructure
For enterprise leaders, the focus has shifted from “what can AI do” to “how do [...]
May

The 4 Metrics That Actually Matter for AI Cluster Performance
In 2026, most teams can get their hands on clusters built with top-tier hardware. But [...]
May

Why Your Team Needs Managed GPUs
In the current era of rapid technological advancement, high performance is a fundamental necessity for [...]
Apr

How to Run AI Workloads on Budget-Friendly GPUs
Organizations assume that running modern AI workloads (particularly inference) requires the latest generation of high-performance [...]
Apr

Secure Your Spot at These HumanX Mixers Co-Hosted by Massed Compute
This year, we’re heading to San Francisco for HumanX from April 6 through April 9, [...]
Apr

How Institutions Are Preparing Students to Build the AI Future
In the late months of 2022, the higher education sector was largely defensive. When ChatGPT [...]
Mar

Why Enterprises Are Bringing Cloud-Like Infrastructure In-House With Neoclouds
For more than a decade, public cloud platforms have transformed how enterprises deploy, scale, and [...]
Mar

Don’t Miss These 3 GTC Happy Hours Co-Hosted by Massed Compute
The real breakthroughs at NVIDIA GTC 2026 will be where the builders meet. This March [...]
Mar

What Is Massed Compute LocalMetal?
Modern enterprises face a critical infrastructure bottleneck as they compete for leadership in the AI [...]
Feb

Why Do Infrastructure Choices Determine the Winners of the AI Race?
Choosing the wrong infrastructure slows your research team down and quietly creates friction across your [...]
Feb

What is the Impact of GPU Shortages in University Research?
Graphics Processing Units (GPUs) are the workhorse of modern computational research, accelerating tasks that would [...]
Feb

What is an AI factory and What is the NeoCloud Advantage?
It is a new class of infrastructure designed for one purpose: turning large volumes of [...]
Jan

Introducing the Industry’s First Integrated GPUaaS & NaaS Offering for Enterprise AI
The “AI Race” is often portrayed as a hunt for silicon. Enterprises scramble to secure [...]
Jan
Why Modern RAG Systems Rely on NVIDIA GPUs
Retrieval-Augmented Generation (RAG) has quickly become one of the most powerful patterns in modern AI [...]
Jan

Does Cloud GPU Rental Make More Sense Than Buying?
Your computer performs countless tasks simultaneously, from browsing social media and writing emails to running [...]
Jan

AI in VFX: AI Face Replacement
AI face replacement is the substitution or modification of faces using artificial intelligence (AI), and [...]
Dec

What Are the Benefits a NeoCloud for Today’s AI and Machine Learning Demands?
AI is a core component of how modern organizations operate, innovate and compete. From large [...]
Dec

What’s behind the NVIDIA’s GPU names: From Ampère to Blackwell
When we see names like Ampere, Lovelace, Hopper or Blackwell on graphics cards or AI [...]
Dec

What is resiliency in cloud computing?
Just a few weeks ago, the infrastructure of Amazon Web Services (AWS) suffered an outage [...]
Dec
Why Are GPUs Essential for Large-scale Scientific Simulations?
Picture this: you and a friend agree to meet somewhere in the city between 5 [...]
Nov

Redefining the Next Generation of AI Compute on the Massed Compute VM Marketplace
The AI landscape is evolving faster than ever, and compute infrastructure is evolving with it. [...]
Nov

What is the Real Role of AI in Modern Entrepreneurship?
The rapid rise of artificial intelligence (AI) has sparked a flood of big promises—none more [...]
Nov

AI in VFX: AI-Assisted Rotoscoping
Imagine needing to create an action scene where the main character is placed in a [...]
Nov

What are the hidden costs of high-performance GPU maintenance?
When we think about high-performance GPU infrastructure, most of us picture raw power: faster computations, [...]
Oct

AI in VFX: What Is Upscaling & How It Works
AI-powered upscaling is revolutionizing the way we enhance and transform visual content. Imagine uncovering a [...]
Oct

What are AI agents?
Just as artificial intelligence was once imagined as a single, all-powerful brain. Today, machine learning [...]
Oct

AI in VFX: AI Motion Capture
For decades, capturing human movement and transferring it to digital characters required tight suits covered [...]
Oct
Bringing AI to your business? Here’s how to keep your data secure in the cloud
You’ve built an AI solution that’s shown real promise. Maybe it’s helped streamline a critical [...]
Oct

AI in VFX: AI object removal & inpainting
Artificial intelligence (AI) object removal and video inpainting are rapidly evolving technologies that let editors [...]
Sep

7 ways cloud GPU solutions save researchers time
Computational power can often be the limiting factor between an idea and its realization. Traditional [...]
Sep

How did modern data centers evolve?
Today, big data and modern databases are the backbone of information management. Did you know [...]
Sep

Behind GPT-5: How OpenAI’s latest model chooses the right response for users
The launch of GPT-5 from OpenAI last month represents a major leap in how artificial [...]
Sep

How do neural network weights help train AI?
If you’ve read even a little about artificial intelligence (AI), you’ve probably seen the term [...]
Aug

How tech offers support for agriculture
In the Midwest, it was once traditional for teenagers to detassel corn. It’s an extremely [...]
Aug

$300M From Digital Alpha and Collaboration With Cisco Accelerates Massed Compute’s AI Infrastructure Expansion
Massed Compute has reached a significant milestone in our mission to accelerate AI innovation. We [...]
Aug

Healthcare: How ambient AI can make the doctor’s office more personal
Visiting your healthcare provider, even in a difficult time, should absolutely not be a frustrating [...]
Aug

Everything you need to know about AI-generated backgrounds
Expensive on-location shoots, elaborate studio sessions, and green screen setups have long been the backbone—and [...]
Jul
Healthcare: AI is improving cancer detection in ways that are too impactful to grasp
In researching and writing about trends in cancer diagnoses and outcomes, and advancements in oncology, [...]
Jul

4 real-world examples of companies solving problems with AI
Artificial intelligence is reshaping how businesses solve problems and improve efficiency. From optimizing warehouse operations [...]
Jul

6 common data challenges when creating a machine learning model (and how to avoid them)
The goal of any data science project is turning raw data into valuable insights for [...]
Jul
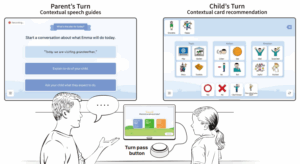
“How about you, Mom?” AI-integrated speech and language tools help nonverbal children learn to converse.
Advancements in technology and science, especially in AI-powered speech tools, in the last two decades [...]
Jul
What are AI tokens and why are they the new AI metric?
Just like ticket sales measure the success of a concert or page views measure the [...]
Jun

Why NVIDIA’s chips dominate the AI market
NVIDIA is the current leader in the global artificial intelligence (AI) chip market and is [...]
Jun

How to understand and read GPU benchmarks correctly
GPU (Graphics Processing Unit) benchmark comparisons are used to measure the performance of a GPU. [...]
Jun

Is my business ready for AI?
When people talk about one of the major appeals of artificial intelligence (AI) for businesses, [...]
Jun

Is GPU computing suitable for big data analytics?
Today, anyone with a basic computer can perform powerful data analysis and extract valuable [...]
May

How is AI Transforming Customer Service?
Thanks to the widespread accessibility of technology, companies have discovered new and revolutionary ways to [...]
May

January Roundup: What’s New in AI Developer Tools
As AI and development tools continue to evolve, January brought several exciting advancements designed to [...]
Mar

How RAG Unlocks Search for AI Models
We’ve all experienced AI hallucinations—those moments when a chatbot or AI assistant confidently provides an [...]
Mar

Is DeepSeek a threat or an opportunity for NVIDIA’s chips?
The launch of DeepSeek, an open-source artificial intelligence model developed in China, generated a wave [...]
Mar

Our Favorite Mindblowing AI Predictions for 2025
In 2025, artificial intelligence is set to redefine industries and unlock new possibilities we’re only [...]
Jan
3 ways to integrate AI into your workflow
Artificial Intelligence (AI) is no longer a futuristic concept limited to tech giants. It has [...]
Jan

How does a virtual desktop interface make AI development easier?
When developing AI, having access to efficient and powerful tools helps move projects forward in [...]
Jan

What are cloud AI developer services?
Until recently, getting involved in AI development required expensive hardware and deep technical expertise—this kept [...]
Dec

What is GPU cloud computing?
GPUs (Graphics Processing Unit) outperform CPUs in tasks like AI, machine learning, 3D rendering, and [...]
Dec

Why is Nvidia considered one of the best AI companies?
Since its founding in 1993, NVIDIA has gone on an impressive journey. It’s evolved from [...]
Nov

Why GPU Benchmarks Matter for Rentable GPUs
In today’s tech world, the high demand for powerful Graphics Processing Units (GPUs) makes renting [...]
Nov

NEW – Fully Prepared ComfyUI Workflows
ComfyUI stands out as a premier application in the realm of image-based Generative AI, boasting [...]
Nov

NVIDIA GPU Display Driver Security Vulnerability – October 2024
NVIDIA recently posted a security bulletin that illustrates several critical vulnerabilities found with NVIDIA drivers. [...]
Nov

Impact of updated NVIDIA drivers on vLLM & HuggingFace TGI
If you are building a service that relies on LLM inference performance, you want to [...]
Oct

Want to build a custom Chat GPT? The top cloud computing platforms to create your own LLM
Want to Build a Custom Chat GPT? Here’s How to Pick the Best Cloud Computing [...]
Sep

What is Hacktoberfest and is it good for beginners?
Hacktoberfest is an annual event that runs throughout October, celebrating open-source projects and the community [...]
Sep

What is AI inference VS. AI training?
When it comes to Artificial Intelligence (AI) models, there are two key processes that allow [...]
Aug

What is generative AI and how can I use it?
While it may seem that AI is a recent phenomenon, the field of artificial intelligence [...]
Aug

Advantages of Cloud GPUs for AI Development
Artificial Intelligence (AI) development has become a cornerstone of innovation across numerous industries, from healthcare [...]
Aug

LLama 3.1 Benchmark Across Various GPU Types
Figure: Generated from our Art VM Image using Invoke AI Previously we performed some benchmarks [...]
Jul

Maximizing AI efficiency: Insights into model merging techniques
What’s a great piece of advice when you venture on a creative path that requires [...]
Jul

NVIDIA Research predicts what’s next in AI, from better weather predictions to digital humans
NVIDIA’s CEO, Jensen Huang, revealed some of the most exciting technological innovations during his keynote [...]
Jul

How do I start learning about LLM? A beginner’s guide to large language models
In the era of Artificial Intelligence (AI), Large Language Models (LLMs) are redefining our interaction [...]
Jun

LLama 3 Benchmark Across Various GPU Types
Update: Looking for Llama 3.1 70B GPU Benchmarks? Check out our blog post on Llama [...]
Jun
GPU vs CPU
Often considered the “brain” of a computer, processors interpret and execute programs and tasks. In [...]
May
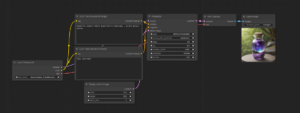
One-Click Easy Install of ComfyUI
ComfyUI provides users with a simple yet effective graph/nodes interface that streamlines the creation and [...]
May

Open Source LLMs gain ground on proprietary models
Recently, there have been a few posts about how open-source models like Llama 3 are [...]
May

Best Llama 3 Inference Endpoint – Part 2
Considerations Testing Scenario Startup Commands Token/Sec Results vLLM4xA600014.7 tokens/sec14.7 tokens/sec15.2 tokens/sec15.0 tokens/sec15.0 tokens/secAverage token/sec 14.92 [...]
Apr


Leverage Hugging Face’s TGI to Create Large Language Models (LLMs) Inference APIs – Part 2
Introduction – Multiple LLM APIs If you haven’t already, go back and read Part 1 [...]
Mar

Leverage Hugging Face’s TGI to Create Large Language Models (LLMs) Inference APIs – Part 1
Introduction Are you interested in setting up an inference endpoint for one of your favorite [...]
Feb
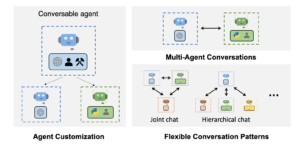
AutoGen with Ollama/LiteLLM – Setup on Linux VM
In the ever-evolving landscape of AI technology, Microsoft continues to push the boundaries with groundbreaking [...]
Nov